arashi1977さんの助け合いフォーラム投稿一覧
ORACLE 詳しくないので間違ってたらごめんなさい。
ただ、ちょっとよくわからないのですが
「停止(SHUTDOWN)は起動(STARTUP)の逆の手順で行われる」という原則に従うと、停止時の最後の手順は以下のようになると考えました。
したがって、理論上の順序は 「5 → 4」 になると理解しております。
これって解説にある順序と違いますよね?
手元の問題集の解説では、正しい停止順序が以下のように記載されていました。
「手元の問題集」が何を指すのかわかりませんが、少なくともご質問の最強問題集の問題 ID で参照できる解説でも同じ順序が記載されています。
なぜ 「4. SGAをメモリーから削除」 が 「5. バックグラウンド・プロセスを停止」 よりも前に行われるのでしょうか?
バックグラウンドプロセスが停止したら、それ以上管理操作が行えなくなるから、ということではないですか?
プロセスがまだ動作している状態(手順5の前)で、そのプロセスが使用している共有メモリ領域(手順4)を先に削除することは、技術的な整合性として正しいのでしょうか?
正常に終了処理を完了する前にプロセスを落とすと終了処理が完了できずに終わってしまうのではないかと思うので、この順序に整合性はあると思います。
起動フロー(手順②・③)では、「メモリの確保が先、プロセスの起動が後」とされています。, 停止がその完全な鏡像(ミラーリング)であるならば
この仮定が正しいのかどうか、というところがメインになるのではと思いますが、そもそも Oracle 公式の記述(参考URL)でも以下のように「SGA メモリー占有中止(=メモリ解放)→ バックグラウンドプロセス停止」となっていますので、「完全な鏡像(ミラーリング)」という仮定が誤っているのではないかと思います。
インスタンスの停止方法
データベース停止の最後の操作は、インスタンスの停止です。データベース・インスタンスが停止すると、SGAではメモリーの占有を中止し、バックグラウンド・プロセスが終了します。
これがダメな理由の解説がよくわかりません。どなたかよろしこお願いします。
「よくわかりません」だと何がわからないのかよくわかりません。
解説を読んでどう理解したのか、AI アシスタントに質問してみてどうだったのかなど、何か理解に向けて取り組んだことや自分なりの解釈はありませんか?あるのであればそれも提示したほうがより良い回答が得られるかと思います。
あきらめたらそこで試合終了ですよね?
前回もこのフレーズありましたが、どういった反応を求めてらっしゃるのでしょうか?
問題文のどこに対する疑問なのかわかりませんが「すでに改善は済ませた」前提だったらそのコメントは当たらないと思いますし、何より SAA の試験なのに「適切な AWS プロダクトを選択して、効果的に適用する」という点を素直に受け止めるのは難しいことでしょうか?
JSON とは違うので、エラーにはならないですね。
$ python3
Python 3.14.3 (main, Feb 3 2026, 15:32:20) [Clang 17.0.0 (clang-1700.6.3.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> ex_data = [
... {"certification": "CCNA ", "vendor": "Cisco", "exam": ["200-301"]},
... {"certification": "CCNP EI", "vendor": "Cisco", "exam": ["350-401", "300-410"]},
... {"certification": "Linux Professional ", "vendor": "LPI", "exam": ["LPIC-1", "LPIC-2", "LPIC-3"]},
... {"certification": "ORACLE MASTER ", "vendor": "Oracle", "exam": ["Bronze", "Silver", "Gold"]},
... ]
...
>>>
設問は
Oracle Databaseで使用できるグループ関数とその説明として、正しい組合せはどれですか(3つ選択して下さい)。
ですので、LISTAGG は「グループ関数」ではあるが 「説明が正しくないので不正解」 というだけですよね。
諦めたらそこで試合終了なのでしょうか。
問題文を最後まで読むことを諦めなければ大丈夫かと思います (^^;
正規表現を学習されるとこの疑問は解消します。「正規表現」で Google 検索した一番上のやつです。
https://userweb.mnet.ne.jp/nakama/
簡単にいうと () は「キャプチャ」のためのもので、今回だと「(RT-..) はマッチした文字列のグループ1番目」という意味になって、後で「グループ1に入ってる文字列」を参照したい時に使えるものです。
ただ、今回の場合だとぶっちゃけ不要なんですよね。これでも同じ結果になります。
no event manager applet check_cdp_router
event manager applet check_cdp_router
event none
action 1.0 cli command "enable"
action 2.0 cli command "show cdp neighbors"
action 3.0 regexp "RT-.." "$_cli_result" <<<ここ
action 4.0 if $_regexp_result eq "1"
action 5.0 puts "Router detected."
action 6.0 else
action 7.0 puts "Router not detected."
action 8.0 end
実行結果はこうです。
Router#event man run check_cdp_router
Router detected.
でもですね…これ実は問題の要件満たしてないんですよね。実はこういう環境です。
Router#sh cdp nei
Capability Codes: R - Router, T - Trans Bridge, B - Source Route Bridge
S - Switch, H - Host, I - IGMP, r - Repeater, P - Phone,
D - Remote, C - CVTA, M - Two-port Mac Relay
Device ID Local Intrfce Holdtme Capability Platform Port ID
test-RT-01 Gig 0/0 148 R B Gig 0/0
Total cdp entries displayed : 1
元々の正解のやつでも同じ結果になります。
Router#conf t
Enter configuration commands, one per line. End with CNTL/Z.
Router(config)#event manager applet check_cdp_router
Router(config-applet)# action 3.0 regexp ".*(RT-..).*" "$_cli_result"
Router(config-applet)#end
Router#show run | sec check_cdp_router
event manager applet check_cdp_router
event none
action 1.0 cli command "enable"
action 2.0 cli command "show cdp neighbors"
action 3.0 regexp ".*(RT-..).*" "$_cli_result" <<<ここ
action 4.0 if $_regexp_result eq "1"
action 5.0 puts "Router detected."
action 6.0 else
action 7.0 puts "Router not detected."
action 8.0 end
Router#event man run check_cdp_router
Router detected.
show cdp neigubors の出力と「RT-で始まる」というのを意識して正規表現とか考える必要があるので、自分だったらこうするかなーと。(なぜか行頭を示す ^ が動かなかった…)
Router#conf t
Enter configuration commands, one per line. End with CNTL/Z.
Router(config)#event manager applet check_cdp_router
Router(config-applet)#action 3.0 regexp "\nRT-.. " "$_cli_result"
Router(config-applet)#end
Router#show run | sec check_cdp_router
event manager applet check_cdp_router
event none
action 1.0 cli command "enable"
action 2.0 cli command "show cdp neighbors"
action 3.0 regexp "\nRT-.. " "$_cli_result"
action 4.0 if $_regexp_result eq "1"
action 5.0 puts "Router detected."
action 6.0 else
action 7.0 puts "Router not detected."
action 8.0 end
Router#event man run check_cdp_router
Router not detected.
ちゃんと行頭のも対応できます。
Router#sh cdp nei
Capability Codes: R - Router, T - Trans Bridge, B - Source Route Bridge
S - Switch, H - Host, I - IGMP, r - Repeater, P - Phone,
D - Remote, C - CVTA, M - Two-port Mac Relay
Device ID Local Intrfce Holdtme Capability Platform Port ID
test-RT-01 Gig 0/0 126 R B Gig 0/0
RT-01 Gig 0/0 179 R B Gig 0/0 <<<要件に合う行
Total cdp entries displayed : 2
Router#event man run check_cdp_router
Router detected.
解説には以下のように記載されていますが、ネクストホップ→出力インターフェースの指定が正しい順序ではないのでしょうか?
どうしてそう判断されたかの根拠はありますか?
参考 URL の先のドキュメントではステップ3として以下のように書かれています。
ipv6 route ipv6-prefix / prefix-length { ipv6-address | interface-type interface-number [ ipv6-address ]} [ administrative-distance ] [ administrative-multicast-distance | unicast | multicast ] [ tag tag ]
prefix-length の次のフィールドは2つ目の interface-type interface-number [ ipv6-address ] の形式で指定するパターンであり、「出力インターフェース ネクストホップアドレス」となると読めるのですが、tani80 さんが参照されたドキュメントでは違うことが書いてあったとかそういうお話でしょうか?
解説に記載がありますが、RB で NAT されているので RC からは 192.168.10.1 は見えておらず、10.10.10.1 として見えているので、10.10.10.1/32 な経路がルーティングテーブルに存在するようにしないといけないんですよね。ですので、「正解にはならないのでしょうか?」とおっしゃっている選択肢の誤答解説にあるとおり
・RC(config)#ip route 192.168.10.1 255.255.255.255 172.16.0.254
この場合、RC→RAへの通信は成功します。しかしRA→RCへの通信の際は、RAからRCへパケットが到達しても、RCはそれに応答するパケットを送信するためのルート情報を持たないため、通信が失敗します。よって、誤りです。
の通りだと思うのですが、そういうお話ではないです?
今回の問題は「サーバ上でssh-keygenをして、作成したサーバの秘密鍵をクライアントに送る」と認識しているので、
ここがちょっと違うんじゃないかなと思います。
まず、設問の通りにコマンドを打つと、「サーバの秘密鍵」ではなくユーザーの鍵を生成するようになるんですよね。
$ ssh-keygen -t ecdsa
Generating public/private ecdsa key pair.
Enter file in which to save the key (/home/user/.ssh/id_ecdsa):
この時点で、「サーバの秘密鍵」を生成しようという意図ではないと読めます。また、ホスト鍵はそもそも自動で生成されますし、手動で作成する場合でも -A を指定するかと思いますので、今回のコマンドラインでは「ホスト鍵」と判断すべき理由はないかと思います。
https://man7.org/linux/man-pages/man1/ssh-keygen.1.html
-A **Generate host keys** of all default key types (rsa, ecdsa, and ed25519) if they do not already exist. The host keys are generated with the default key file path, an empty passphrase, default bits for the key type, and default comment. If -f has also been specified, its argument is used as a prefix to the default path for the resulting host key files. This is used by /etc/rc to generate new host keys.
何より、「サーバの秘密鍵」をクライアントに送る理由はありません。参考の「ホスト認証」の部分を再度ご確認いただくのが良いかなと思います。
すみません、質問の意味がよくわからないのですが
runtsもカウンタ上がるのかと思ったんですが
CatA,CatBのスイッチも0
これは何をみて言っていますか?コマンド実行例のことであれば、その時は runts が 0 だったというだけであって duplex 不一致だから「必ず」runts も上がると言えるわけではない、というだけの話かと思います。
参考 URL の先もご確認いただくのが良いかなと思います。
はい。過去のポストは見ましたが、秘密鍵を送信する、という部分について、やはり納得できません。
「送信する」とはどこにも書いていませんよ。「安全に持ち運ぶ」です。例えば
- 本番サーバで自分のアカウントを発行してもらった
- 自分のアカウントでログイン
- 本番サーバ上で鍵ペアを生成
- リモートから入れるように「勝手に自分の PC 上で生成した公開鍵を登録」するのではなく、サーバ上で生成した公開鍵を authorized_keys に登録
- 生成した秘密鍵をリモートホストまで「安全に持ち運ぶ」
- 本番サーバ上の秘密鍵を削除する
- リモート接続用に使用できるよう持ち運んだ秘密鍵を設定する(持ち運び方はここでは指定されていないが、許可された方法と理解するので良いかなと)
という運用をイメージしてみたら
- 本人が持ち運んでおり、外部に漏らしてはいない
- 速やかにサーバ側の秘密鍵を削除しており、管理者は管理していない(まさかすべてのユーザーが生成した秘密鍵を含むすべてのファイルを管理者が保持している、みたいな話はさすがに考慮しなくて良いかと)
ので、特に問題はないと思うのですが…
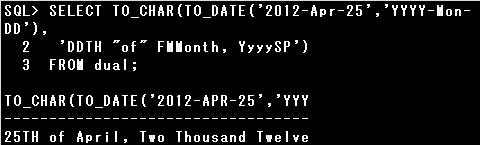
設問では 「25TH of April, Two Thousand Twelve」 と出力されるとのことですが、「25TH of April, Two thousand twelve」が正しいのではないでしょうか。
確認なのですが、解説の実行例がおかしいのではないか、というご指摘でしょうか?
(私の手元に実行環境がないので自信がないのですが、kevinmm さんのところでの実行結果と異なる、ということなのだろうか?と思いまして)
参考 URL についている「BGPへのOSPFルートの再配布について」を参照されると良いかと思います。
このドキュメントでは、CiscoルータでのOpen Shortest Path First(OSPF)からBorder Gateway Protocol(BGP)への再配布の動作について説明します。
再配布を完了するには、それぞれのルートを再配布するために、internal、external、nssa-externalareなどの特定のキーワードが必要です。
OSPF から BGP への再配布をキーワードなしで設定すると、デフォルトでは、OSPF のエリア内ルートとエリア間ルートだけが再配布されます。
また、再配送先によって挙動が変わるのであれば、上の設問ははOSPFからの再配送ですが、EIGRP/BGPからのものについても挙動の変化はあるのでしょうか?
EIGRP は経路が D と D EX の2種類しかないからかもしれませんが、OSPF のように match キーワードがないので特別な挙動の変化はないはずですね。
Router(config)#router bgp 100
Router(config-router)#redistribute ospf 1 match ?
external Redistribute OSPF external routes
internal Redistribute OSPF internal routes
nssa-external Redistribute OSPF NSSA external routes
Router(config-router)#redistribute eigrp 1 ?
metric Metric for redistributed routes
route-map Route map reference
<cr>
自分の Ubuntu 環境では解説の通りでした。
どちらかというと、markun_D さんの出力が「マッチするファイルが存在しない」時のエラーメッセージなので、ちゃんとそこにファイルがあるのかが気になりました。 ls だけやった場合と ls file?.txt をやった場合の結果ってどうなるでしょうか?
$ mkdir 2623
$ cd 2623
$ ls <<< ディレクトリの中は空っぽ
$ ls file?.txt
ls: cannot access 'file?.txt': No such file or directory <<< ファイルが存在しないので、このエラーが出てる
$ touch file1.txt file2.txt file303.txt file004.txt fileA.txt
$ ls
file004.txt file1.txt file2.txt file303.txt fileA.txt
$ ls file?.txt <<< ファイルがある場合はちゃんと出る
file1.txt file2.txt fileA.txt
$ rm * <<< ここでまたファイルを削除してみる
$ ls file?.txt
ls: cannot access 'file?.txt': No such file or directory <<< 同じエラーメッセージ
うーんと
ネットワーク外のアドレスをデフォルトゲートウェイに指定する事は可能です。
指定可能なのはわかります。それが「誤った設定」かどうかがこの選択肢のポイントですよね?
そして
当然同一ネットワークに無いので、デフォルトゲートウェイに対するルーティングを「route add 192.168.10.2 192.168.10.2 IF 10」等でPCに設定する必要はあり、ルータ側にも192.168.10.5へのルーティングを設定する必要はありますが、この構成でも通信は可能です。
そしてルーティングに関する設定は設問では省略されているため判断できません。
設問の条件にない設定を追加することで「この選択肢は正しいとは言い切れない」というのは NG です。
それが仮に OK なのであれば、「通信ができない理由はなぜか」みたいな設問に対して「ルータの特定処理がバグを踏んでいて異常動作しているから」というのも「設問に明記されていないので否定できない」と理由づけして「正答ではない!」と言い張ることも可能になってしまいます。
また、
そもそもPCAとルータが通信不可であるかが設問に無いため、
すでに言及いただいているとおり「同一ネットワークに無い」のですから通信不可だと判断すべきなのはご理解いただけているものと思っています。
この問題は「同一ネットワークに属さないアドレスをデフォルトゲートウェイとして設定しているので利用できない→誤った設定をしている」と判断できるかを問われているものであり、「こうやればできるのだから、その可能性を否定できるように明記していないのがおかしい」として押し通すのは無理筋で、「書かれていないものを追加の条件として【なんとかできるようにする方法を見つける】」問題ではないとご理解いただくのが良いかなと思います。
3. 同期の条件が整っていれば、リビジョン番号が一番大きなものにVLAN情報を同期する⭕️
「リビジョン番号が一番大きなものに【自身の】VLAN情報を同期する」と読めるのでそんなに違和感は感じていなかったです。逆に「に」を「に対して」に変換する方がちょっと無理矢理感が感じられました。
とはいえ、「一番XXなもの【の】VLAN情報【に】同期する」の方が誤認はしにくいかもしれませんね。